Warning: Paket 'stargazer' wurde unter R Version 4.1.2 erstellt
Hlavac, Marek (2022). stargazer: Well-Formatted Regression and Summary Statistics Tables.
R package version 5.2.3. https://CRAN.R-project.org/package=stargazer
load("data/dataset_AJR2001.Rdata")
head(data)
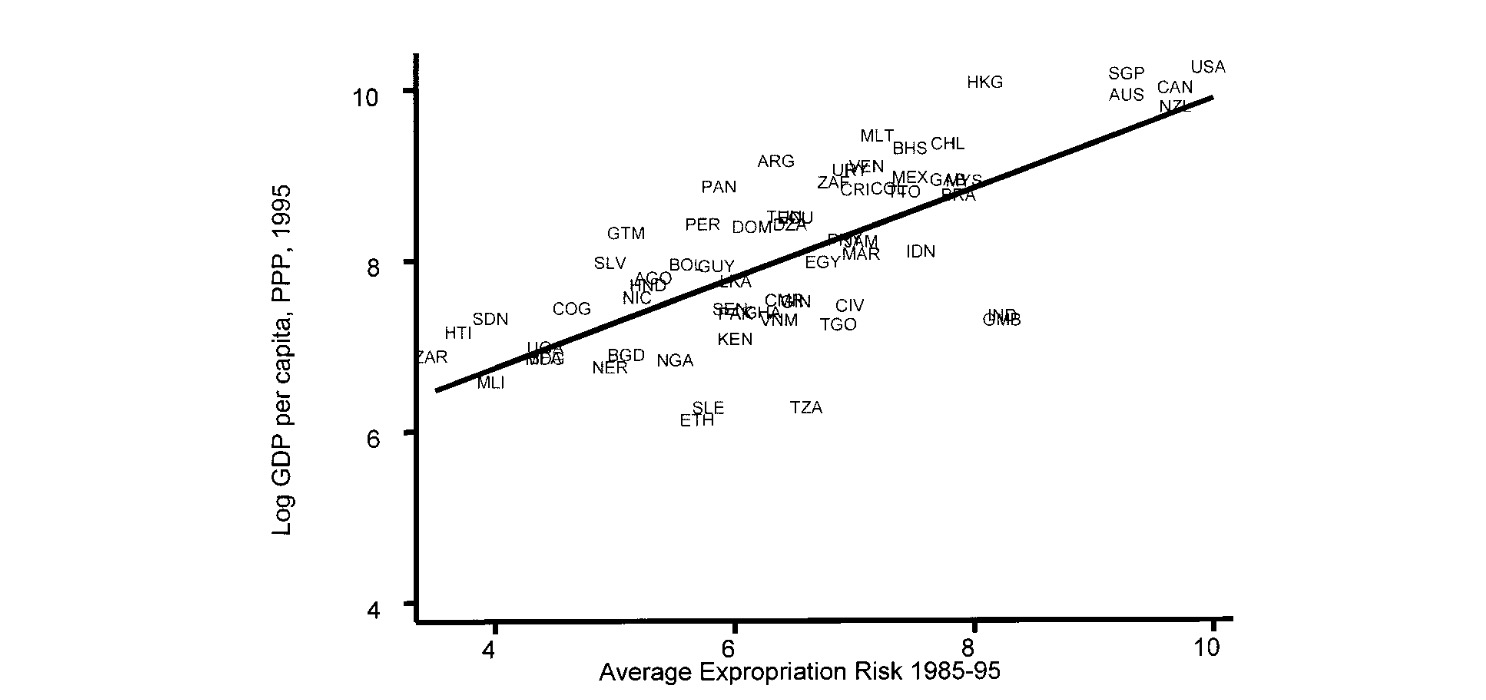
m_T2_world_1 <- lm(logpgp95 ~ avexpr, data=data)
m_T2_base_1 <- lm(logpgp95 ~ avexpr, data=data[which(data$baseco==1),])
#latitude added
m_T2_world_2 <- lm(logpgp95 ~avexpr + lat_abst,data=data)
m_T2_base_2 <- lm(logpgp95 ~ avexpr + lat_abst, data=data[which(data$baseco==1),])
# continent dummies
m_T2_world_3 <- lm(logpgp95 ~avexpr + lat_abst + asia + africa + other,data=data)
m_T2_base_3 <- lm(logpgp95 ~ avexpr + lat_abst + asia + africa + other, data=data[which(data$baseco==1),])
# other dependent variable
m_T2_world_4 <- lm(loghjypl ~avexpr, data=data)
m_T2_base_4 <- lm(loghjypl ~ avexpr, data=data[which(data$baseco==1),])
all_res <- list(
m_T2_world_1, m_T2_base_1,
m_T2_world_2, m_T2_base_2,
m_T2_world_3, m_T2_base_3,
m_T2_world_4, m_T2_base_4
)
coef_names <- c("Average Protection", "Latittude","Asia dummy", "Africa dummy", "Other")
note <- "Nitzuen lorem"
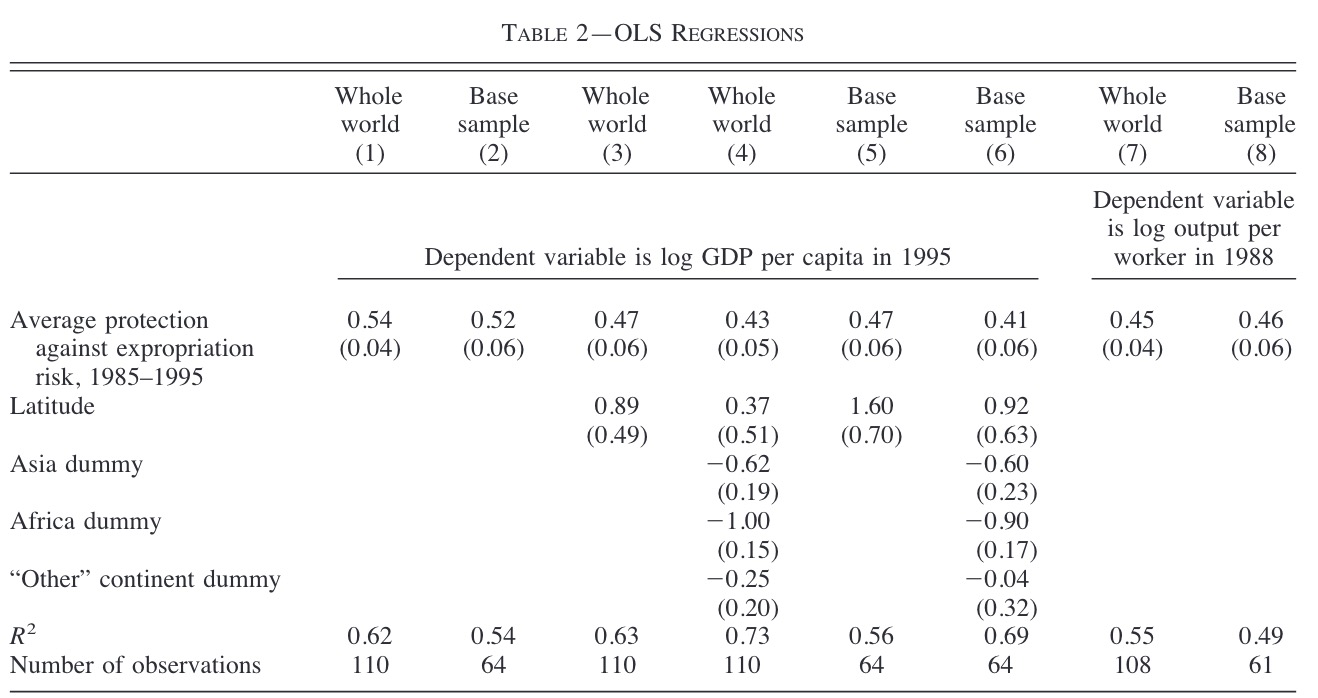
stargazer(all_res,
type="html",
out="data/Table2_stargazer.html", omit = "Constant",
notes.label = note,
dep.var.labels = c("log GDP per Capita", "log output per worker"),
covariate.labels = coef_names
)